
Take BSc Tuition from the Best Tutors
Search in

Answered on 16/03/2019 Learn BSc Computer Science

Ruhinaz
Tutor for all studying n needing students
Clear the basic studies already done in 1st n 2nd year of bsc subject then go through the syllabus and note down the things u know then u cann make ur own notes and google will help u in that as per a tutor take help of best IT tutor for hard topics who can make you understand better than 1st
read lessLesson Posted on 23/12/2017 Learn BSc Computer Science
C++: Passing A Function As an Argument

Ashutosh Singh
Subject matter expert (Computer Science & Engineering) at Chegg India since June 2019. Teaching programming...
#include
using namespace std;
int sum(int a,int b)
{
return a+b;
}
void f2(int (*f)(int,int),int a,int b) //'*f' is a POINTER TO A FUNCTION whose RETURN TYPE is //'int' and arg type (int,int) . Here, '*f' is FORMAL PARAMETER
{
cout<<sum(a,b)<<endl;
}
int main()
{ int (*p1)(int,int)=∑ //Here, '*pf1' is ACTUAL PARAMETER
f2(sum,10,20); //NAME OF A FUNCTION IS ITSELF A POINTER TO ITSELF
f2(p1,20,79);
return 0;
}
Lesson Posted on 09/11/2017 Learn BSc Computer Science

GCC
Java 9 is here! A major feature release in the Java Platform Standard Edition is Java 9
Lets see what more it offers more than its previous versions
Moreover it includes enhancements for microsoft windows and MAcOS OS platforms
read less
Take BSc Tuition from the Best Tutors
Lesson Posted on 23/08/2017 Learn BSc Computer Science

SR-IT Academy
SR - IT Academy is one of the leading tutorial point providing services like tutoring and computer training...
while (left <= right)
The loop invariant is:
all items in A[low] to A[left-1] are <= the pivot
all items in A[right+1] to A[high] are >= the pivot
Each time around the loop:
left is incremented until it "points" to a value > the pivot
right is decremented until it "points" to a value < the pivot
if left and right have not crossed each other,
then swap the items they "point" to.
Lesson Posted on 07/08/2017 Learn BSc Computer Science
Deadlocks In Distributed Systems
SR-IT Academy
SR - IT Academy is one of the leading tutorial point providing services like tutoring and computer training...
Lesson Posted on 05/07/2017 Learn BSc Computer Science
Introductory Discussions On Complexity Analysis

Shiladitya Munshi
Well, I love spending time with students and to transfer whatever computing knowledge I have acquired...
What is Complexity Analysis of Algorithm?
Complexity Analysis, simply put, is a technique through which you can judge about how good one particular algorithm is. Now the term “good” can mean many things at different times.
Suppose you have to go from your home to the Esplanade! There are many ways from your home that may lead to Esplanade. Take any one, and ask whether this route is good or bad. It may so happen that this route is good if the time of travel is concerned (that is the route is short enough), but at the same time, it may be considered bad taking the comfort into considerations (This route may have many speed breakers leading to discomforts). So, the goodness (or badness as well) of any solution depends on the situations and whatever is good to you right now, may seem as bad if the situation changes. In a nutshell, the goodness/badness or the efficiency of a particular solution depends on some criteria of measurements.
So what are the criteria while analyzing complexities of algorithms?
Focusing only on algorithms, the criteria are Time and Space. The criteria Time, judges how fast or slow the algorithms run when executed; and the criteria Space judges how big or small amount of memory (on primary/hard disks) is required to execute the algorithm. Depending on these two measuring criteria, two type of Algorithm Analysis are done; one is called Time Complexity Analysis and the second one is Space Complexity Analysis.
Which one is more important over the other?
I am sorry! I do not know the answer; rather there is no straight forward answer to this question. Think of yourself. Thinking of the previous example of many solutions that you have for travelling from your home to Esplanade, which criteria is most important? Is it Time of Travel, or is it Comfort? Or is it Financial Cost? It depends actually. While you are in hurry for shopping at New Market, the Time Taken would probably be your choice. If you have enough time in your hand, if you are in jolly mood and if you are going for a delicious dinner with your friends, probably you would choose Comfort; and at the end of the month, when you are running short with your pocket money, the Financial Cost would be most important to you. So the most important criterion is a dynamic notion that evolves with time.
Twenty or thirty years back, when the pace of advancement of Electronics and Computer Hardware was timid, computer programs were forced to run with lesser amount of memory. Today you may have gigantic memory even as RAM, but that time, thinking of a very large hard disk was a day dreaming! So at that time, Space Complexity was much more important than the Time Complexity, because we had lesser memory but ample times.
Now the time has changed! Now a day, we generally enjoy large memories but sorry, we don’t have enough time with us. We need every program to run as quick as possible! So currently, Time Complexity wins over Space Complexity. Honestly, both of these options are equally important from theoretical perspective but the changing time has an effect to these.
read lessTake BSc Tuition from the Best Tutors
Lesson Posted on 05/07/2017 Learn BSc Computer Science
A Tutorial On Dynamic Programming
Shiladitya Munshi
Well, I love spending time with students and to transfer whatever computing knowledge I have acquired...
What is Dynamic Programming?
Dynamic Programming, DP in short, is an intelligent way of solving a special type of complex problems which otherwise would hardly be solved in realistic time frame.
What is that special type of problems?
DP is not best fit for all types of complex problems, it is well suited for the problems with following characteristics only:
Wait. Don't jump into any conclusion right now. We have not studied the DP procedures yet! we are currently studying the nature of DP problems only. So it will be too early to compare Divide and Conquer with DP.
But this is true, that just a mere look at the characteristics of DP problems gives a feeling that DP is close to Divide and Conquer. But there is a MAJOR difference, in Divide and Conquer, at any stage, the sub problems enjoy No Inter-Dependencies.
Let us put this on hold. We will revert back to this topic once more only after we have got some experience in DP. But for the time being, take it from me that DP and Divide & Conquer are not same.
Why do not you say how DP works?
DP works as simple as possible. After the problem is broken down to trivial sub-problems in levels, DP starts solving the sub problems bottom up. Once a sub problem is solved, solution is written down (saved) into a table so that if the same sub problem reappears, we get a ready made solution. This is done in every level.
What is so special about this process?
Yes. It is special. See while you decompose a problems into sub problems, sub problems into sub sub problems and so on, you ultimately reach to a point when you need to solve the same sub problems many a times. And this "many" is not a child's play in real life. Lots of computational resources are unnecessarily spent on this which makes the process sluggish with poor time complexity values.
With DP you can avoid the re computations of the same sub problems.This will save a lot of time and other computational resources. But there are table look ups for solving reappearing sub problems, and this is not going to offer a bed of roses. This will surely take some time, but with hashing and some other smart alternatives, table look ups can be made easy.
Getting out of my head! Show me how DP works with an example.
Lets think of Fibonacci series. We know that Fib(n) = Fib(n-1) + Fib(n-2). Hence to compute Fib(4),
Fib(4) = Fib(3) + Fib(2)
= (Fib(2) + Fib(1)) + Fib(2)
= ((Fib(1) + Fib(0)) + Fib(1)) + Fib(2)
= ((Fib(1) + Fib(0)) + Fib(1)) + (Fib(1) + Fib(0))
This could easily be done with Divide and Conquer with recursion. But there will be several call for the trivial case Fib(1) and Fib(0).
But in DP style we can think that
Fib(4) ------------------- level 0
Fib(3) + Fib(2) ------------------ level 1
Fib(2) + Fib(1)-------------------------- level 2
Fib(1) + Fib(0) -------------------------------- level 3
There will be only two calls of Fib(1) and Fib(0) altogether (shown in violet at level 3). The second Fib(1) (shown in red at level 2) will not be called at all as the result of that is already with us. Similarly Fib(2) (shown in green at level 1) will not be called at all as it has already been computed at level 2. In this way we could avoid re-computations in two occasions.
This is the strength of DP. This strength seems trivial with this trivial example, but as the problem size will grow, this strength will seem to have prominent advantage. Just Think of fib(100)
Is Dynamic Programming a process to find solution quicker?
Yes it is, but the nature of the solution we are talking to is an optimal solution not the exact one. The principle of optimality applies if the optimal solution to a problem always contains optimal solutions to all subproblems . Take the following example:
Let us consider the problem of making N Rupees with the fewest number of Rupee coins.
Either there is a coin of value N Rupees (Exact Solution), or the set of coins making up an optimal solution for N Rupees can be divided into two nonempty subsets, n1 Rupees and n2 Rupees (Optimal Solution).
If any of the n1 Rupees or n2 Rupees, can be made with fewer number of coins, then clearly N can be made with fewer coins, hence solution was not optimal.
Tell me more on Principle of Optimality:
The principle of optimality holds if
Every optimal solution to a problem contains optimal solutions to all subproblems
The principle of optimality does not say
If you have optimal solutions to all subproblems then you can combine them to get an optimal solution
Example: If we have infinite numbers of coins of 1cents, 5 cents, 10 cents only then optimal solution to make 7 cents is 5 cents + 1 cent + 1 cent, and the optimal solution to make 6 cents is 5 cents + 1 cent, but the optimal solution to make 13 cent is NOT 5 cents + 1 cent + 1 cent + 5 cents + 1 cent
But there is a way of dividing up 13 cents into subsets with optimal solutions (say, 11 cents + 2 cents) that will give an optimal solution for 13 cents. Hence, the principle of optimality holds for this problem.
Let us see one example where Principle of Optimality does not hold.
In the following graph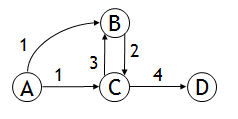
The longest simple path (path not containing a cycle) from A to D is A->B->C->D. However, the sub path A->B is not the longest simple path from A to B (A->C->B is longer)
The principle of optimality is not satisfied for this problem. Hence, the longest simple path problem cannot be solved by a dynamic programming approach.
Can you give me a thorough example of DP?
Why not! Following is an example of working of Dynamic Programming. It presents a comparative analysis of working of DP with the working of Divide & Conquer.
Let us consider the Coin Counting Problem. It is to find the minimum number of coins to make any amount, given a set of coins.
If we are given with a set of coin of 1 unit, 10 units and 25 units, then to make 31, how many minimum numbers of coins are required?
Let us check whether the greedy method will work or not. Greedy Method says that just choose the largest coin that does not overshoot the desired amount. So at the first step, we will take one coin of 25 units and then successively in each of next six steps, we will take one 1 unit coin. So ultimately the solution of Greedy Method is 31 = 25 + 1 + 1 + 1 + 1 + 1 + 1 (Total 7 nk!umbers of coins needed)
But evidently there is better solution like 31 = 10 + 10 + 10 + 1 (only 4 numbers of coins are needed).
Hence Greedy Method will never work.
Now let us check whether any better algorithm exists or not! What about the following?
To make K units:
If there is a K unit coin, then that one coin is the minimum
Otherwise, for each value i < K,
Find the minimum number of coins needed to make i units
Find the minimum number of coins needed to make K - i units
Choose the value of i that minimizes this sum
Yes. This will work. This is actually following Divide & Conquer Principle but there are two problems with this. This solution is very recursive and it requires exponential amount of work to be done.
Now, if we fix the given set of coins as 1, 5, 10, 21, 25 and if the desired amount is 63, then the previous solution will require solving 62 recursive sub problems.
What If we think to choose the best solution among?
In this case, we need to solve only 5 recursive sub problems. So obviously, this second solution is better than the first solution. But still, this second solution is also very expensive.
Now let us check how DP can solve it!
To make it shorter in length, let us think that desired value is 13 units and the set of coin given is 1 unit, 3 units, and 4 units.
DP solves first for one unit, then two units, then three units, etc., up to the desired amount and saves each answer in a table (Memoization). Hence it goes like
For each new amount N, compute all the possible pairs of previous answers which sum to N
For example, to find the solution for 13 units,
First, solve for all of 1 unit, 2 units, 3 units, ..., 12 units
Next, choose the best solution among:
This will run like following:
There’s only one way to make 1unit (one coin)
To make 2 units, try 1 unit +1 unit (one coin + one coin = 2 coins)
To make 3 units, just use the 3 units coin (one coin)
To make 4 units, just use the 4 units coin (one coin)
To make 5 units, try
To make 6 units, try
Etc.
Ok. I got it but how could you say that computationally this is the best?
The first algorithm is recursive, with a branching factor of up to 62. Possibly the average branching factor is somewhere around half of that (31). So the algorithm takes exponential time, with a large base.
The second algorithm is much better—it has a branching factor of 5. Still this is exponential time, with base 5.
The dynamic programming algorithm is O(N*K), where N is the desired amount and K is the number of different kinds of coins.
So I don’t hesitate to say that computationally, DP algorithm works best among these threes.
What is this Matrix Chain Multiplication Problem?
Suppose we have a sequence or chain A1, A2, …, An of n matrices to be multiplied. That is, we want to compute the product A1A2…An. Now there are many possible ways (parenthesizations) to compute the product.
Let us consider the chain A1, A2, A3, A4 of 4 matrices. Now to compute the product A1A2A3A4,there are 5 possible ways as described below:
(A1(A2(A3A4))), (A1((A2A3)A4)), ((A1A2)(A3A4)), ((A1(A2A3))A4), (((A1A2)A3)A4)
Each of these options may lead to the different number of scalar multiplications, and we have to select the best one (option resulting fewer number of Scalar Multiplications)
Hence the problem statement looks something like: “Parenthesize the product A1A2…An such that the total number of scalar multiplications is minimized”
Please remember that the objective of Matrix Chain Multiplication is not to do the multiplication physically, rather the objective is to fix the way of that multiplication ordering so that the number of scalar multiplication gets minimized.
Give me one real example:
Ok. But before I show you one real example, let us revisit the algorithm which multiplies two matrices. It goes like following:
Input: Matrices Ap×q and Bq×r (with dimensions p×q and q×r)
Result: Matrix Cp×r resulting from the product A·B
MATRIX-MULTIPLY(Ap×q , Bq×r)
In the above algorithm, scalar multiplication in line 5 dominates time to compute C Number of scalar multiplications read less
Lesson Posted on 05/07/2017 Learn BSc Computer Science
Do You Give Enough Importance In Writing Main () In C Language?
Shiladitya Munshi
Well, I love spending time with students and to transfer whatever computing knowledge I have acquired...
I am sure; you guys are quite familiar with C programming, especially, while it comes to write the first line of your main function. In my class, I have seen many of my students are writing main function with many different forms.
Some portion of students write like main(), some write main(void), again some of the students write void main(void) and int main(void). Now the question is which one is right?
All are right. Generally you write your C programs with Turbo C editor, or with any other, and generally they do not complain if you write any of them. But still, there is a factor of theoretical perfection. Trivial programming exercises may not be affected with whatever way you follow to declare main function, but in critical cases, your decision may make differences. This is why you should know which one is theoretically perfect.
As we always know that main is a function which gets called at the beginning of execution of any program. So like other functions, main must have a return type and it must expect arguments. If you are not calling your program (or your main likewise) from the command prompt, your mainfunction should not bother for any arguments, so actually you should call your main with void argument, like main(void).
Now you may raise a point that main() itself suggest that no arguments are passed, so what is wrong with it? See one thing, in your current compiler, the default argument is void, but the same may not be true with other compilers or platforms. So you may end up with portability issues! Keep in mind, A Good Programmer Never Rely On Defaults. So please don’t rely on default things any more, clearly write that your main function is not expecting any arguments by writing main(void).
You already have an idea that a function can never work unless and until it is being called by any other program component. This is true for main also. The function main must be called by someone! Who is that? Who calls main function? It is the operating system who calls main function. Now the thing is, your operating system may decide to do any other job according to the success or failure of running your main function. It may so happen that if your program runs successfully, operating system will call a program P1, and if your program does not work, your operating system will call another program P2. So what if your operating system has no idea that your program did run actually or not? There lies the importance of return type of main. Your main function should return something to your operating system back to indicate whether it has ran successfully or not. The rule is if operating system gets an integer 0 back, it takes as main has ran successfully and any non zero value indicates the opposite. So your main program should return an integer. Hence you should write int main(void). Just to add with this, don’t forget to return 0 at the end of your main program so that, if all of your codes run successfully, your main function is capable of returning 0 to the operating system back, indicating that it was a success.
In this point you may argue, that your programs runs quite well even if you do not provide return type to main and you just write main(void). How come it is possible?
Once again, at your age, you are writing just some of trivial academic codes. The situations here are not such critical that your operating system may decide any other thing depending on the success or failure of your main(). But, in near future, you are to write such critical programs, so get prepared from now.
Cool, so to conclude, int main(void) is perfect to write and I encourage you to write like that along with a return 0 at the last line.
read lessLesson Posted on 05/07/2017 Learn BSc Computer Science
What Is the Difference Between Function And Subroutine?
Shiladitya Munshi
Well, I love spending time with students and to transfer whatever computing knowledge I have acquired...
Take BSc Tuition from the Best Tutors
Answered on 22/03/2017 Learn BSc Computer Science

Kousalya Pappu
Tutor
UrbanPro.com helps you to connect with the best BSc Tuition in India. Post Your Requirement today and get connected.
Ask a Question
The best tutors for BSc Tuition Classes are on UrbanPro

The best Tutors for BSc Tuition Classes are on UrbanPro









